
By Stephanie Kiefer Jefferson, Solution Consultant
Did you get a chance to watch the AIIM webinar where David Jenness, Portfolio Marketing Manager and ECM Messaging Lead at IBM, and Richard Medina, Co-Founder and Principal Consultant at Doculabs, chat about the advances in cognitive capture?
Have you played around with Datacap Insight Edition from IBM? If you have, you will know that this is not your mother’s capture technology!
This year Pyramid Solutions was presented with the challenge of extracting key information from complex medical documents. This is a daunting task and at first glance, you might say No way, that’s not possible. Some people’s medical histories could be a novel – they’re hundreds of pages long and maybe even reach one thousand! AND medical documents are filled with words that look like gibberish.
Well, if you attempt this with “old-school” capture capabilities, it will be a challenge for sure. BUT, this is what the cognitive capabilities in Datacap Insight Edition were made for!
Some of you may also have the same kind of challenge in your job — maybe it is extracting key information from mortgage packages or insurance claims or even customer communications. The tools and techniques discussed here can be of use for any unstructured document.
What is Our Challenge With Capture and Complex Documents?
In the webinar, Jenness mentions how Pyramid Solutions is applying Datacap Insight Edition in the life insurance industry. This industry was of particular interest to us because life insurers capture and process some of the most complex documents (i.e. attending physician statements (APS) which average 200-300 pages). (Read more about the complexity of life insurance applications here.)
In life insurance, when a new customer applies for a policy, the underwriter must assess the risk of providing insurance. The underwriter will gather information from a variety of sources to make this decision, medical history being key.
Where traditional capture systems fall short is they can only capture and extract information from known and predictable document types.
In our case, the only such document is the life insurance policy application. Since this document originates internally, the life insurance company has full control over what this looks like. Datacap can recognize and extract fields, easy peasy.
But, what about everything else? What about all those office reports and lab results with unlimited variation? Every doctor, hospital and lab will have its own format — probably many different formats. It’s the same in banking, insurance and government — there is an unlimited supply of unstructured, unexpected documents. Thank goodness for IBM and Datacap Insight Edition. Let’s look at a few of the methods we utilize.
How to Capture Key Information
Let’s get back to Datacap.
Label/Value Pairs
Cognitive capture provides the ability to recognize a name/value pair and extract the data. We don’t even have to tell it what labels to look for. Here’s a snippet from an office visit report. Datacap can extract these for use by the application. Things like Name, Diagnosis, PF Reference and Pred Volume might be useful. Label/value pairs are usually in the headings of documents, but not always. Fortunately, it doesn’t matter, Datacap can dig them out wherever they reside.
Pre-Built Extractors
Here’s where it gets fun.
Datacap provides two methods of cognitive extraction: a built-in integration into BigInsights System T and an available integration into Bluemix Natural Language Understanding. Both engines have a list of pre-built annotators that can find data like People, Date, Location, Organization and Company. Of particular interest in our application are Anatomy, Drug, Medical Condition and Facility. There are even pre-built extractors for TV Show, Actor, Music Group, Animals …. I think it would be fun to work on a project that utilizes some of those extractors! The annotators use Analytics and Natural Language Processing to find keywords in your documents wherever they exist.
 Custom Extractors
Custom Extractors
Can’t find an out-of-the-box extractor to suit your needs? Build your own!
Both cognitive engines provide a graphical method of building custom extractors (BigInsights Text Analytics and IBM Watson Knowledge Studio). For an insurance claim scenario, these might be Account Number or Claim Amount. In our medical extraction use case, we built extractors to make a distinction between patient and doctor name and also to extract a whole slew of lab results.
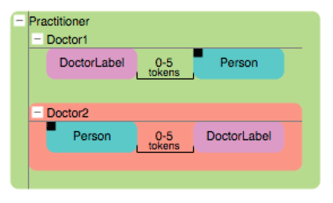
Extractors can be a combination of literals, dictionary terms, regular expressions or proximity rules. Here’s an example of a ‘Practitioner’ extractor that combines the out-of-the-box Person extractor with a Dictionary extractor to find references to a doctor.
Custom extractors provide a very powerful feature for complex cognitive extraction.
Wave the White Flag
Some extraction is really hard, like impossible! Consider the following doctor’s handwriting.

I don’t care what you’ve been told about today’s powerful handprint extraction software, there is no software on earth that will read that handwriting. But, since the doctor took time to make some notes, it’s likely to be important.
Our Team devised a technique for recognizing blocks of handwritten text. Our solution does not read the text, but it recognizes the fact that it exists and alerts an underwriter to visually inspect it. The underwriter can bookmark the area if it does contain valuable information about a condition or prescription. (Wait, bookmark? What’s that? More on that later …)
What to do With All This Data?
So, I said that we’re applying Datacap Insight Edition in the life insurance industry. We’re doing this in a cognitive solution we built specifically for life insurance to make life insurance underwriting easier.
Make it Easy to Interpret
A big part of the solution is extracting key medical information from all those medical documents we talked about earlier. We present this information in a pictorial summary that shows medical conditions and prescriptions along a timeline of the patient’s life. Using this information, an underwriter can quickly notice areas of concern and focus their investigations there.
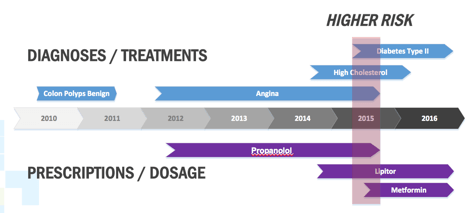
Make it Easy to Find
What’s useful to underwriters is if we present the evidence in a summarized fashion and give them tools to navigate the extensive documents.
That’s where bookmarks come in.
Pyramid eXpeditor for Content has a bookmarking viewer capability where users can mark locations of a document, either programmatically (like from Datacap) or manually by a user.
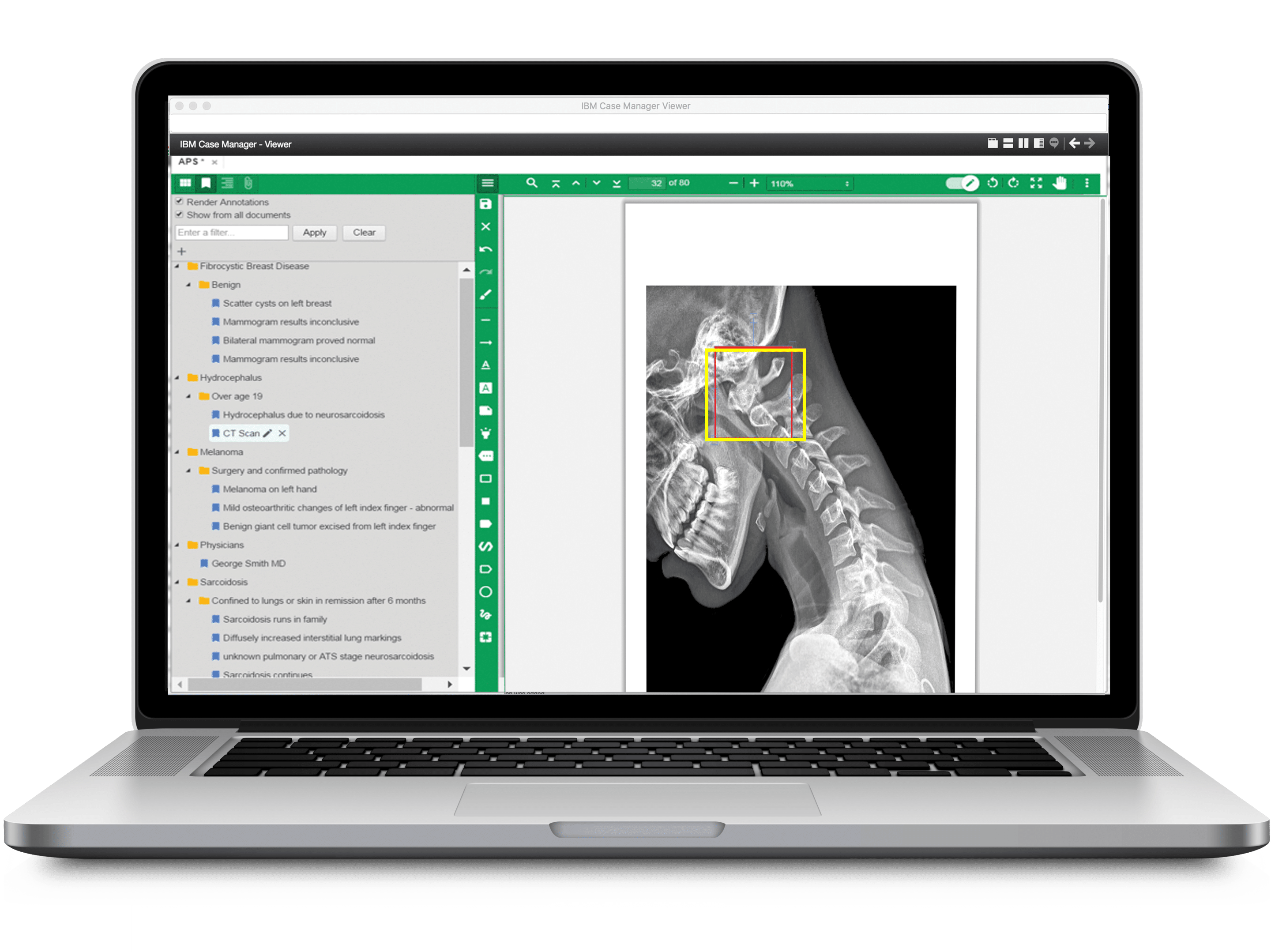
Datacap did the work to extract patient information, health conditions and any prescription information, and it sends all this data to IBM Case Manager as bookmarks in the document for an underwriter to investigate. This includes the handwriting. The underwriter can then understand the subject of the handwriting and determine if she should manually create a bookmark.
The Result of Cognitive Capture
Using Datacap Insight Edition, cognitive technology and bookmarking, we are able to extract key details from complex medical records, and summarize them in a way that allows an underwriter to gain valuable insight from the documents, without having to skim the entire document to find it.
The timeline and associated bookmarks ease the difficult job of a life insurance underwriter by giving them direct access to the information they need to determine the insurance risk. It also enables them to fast-track more simple applications so they can spend more time reviewing applications that truly demand their attention.
You can use these techniques and tools in any industry, any use case, any unstructured documents. Since it is a cognitive tool, Datacap Insight Edition continually learns and advances. I’m always intrigued by the unique ways other organizations use these capabilities and I’m excited to hear what cognitive magic will be next! I hope by sharing Pyramid Solutions’ use-case for it, you have a better idea as to what cognitive capture could do for your organization.
About the Author: I’m a Solution Consultant and spend my days helping clients come up with new and unique ways to utilize the IBM ECM products. I just had my one year anniversary at Pyramid Solutions, but I’ve been working with IBM ECM products for over 20. When I’m not on my laptop, I can usually be found running plumbing, hanging drywall or laying bricks for our historic home renovation. If you can’t find me there, I’m sitting on the beach in the Outer Banks of North Carolina doing absolutely nothing!