
IBM Content Navigator provides a fantastic mechanism to include custom functionality through the use of plug-ins. Developing plug-ins can be a bit intimidating, so here are some basics for IBM Content Navigator plug-in development.
To start, let’s quickly understand the different functionalities you can add within Content Navigator:
- Actions
- Features
- Layouts
- Menus
- Menu Types
- Open Actions
- Request Filters
- Response Filters
- Services
- Viewers
Creating a New IBM Content Navigator Plug-In
IBM made it simple to get started with plug-in development. Creating a new plug-in is as simple as creating a new project in Eclipse or RADS. All of the instructions in this post are for Eclipse, but should be easily translatable to RADS.
Before you are able to develop plugins, you will need to install the IBM Content Navigator and External Data Services plug-ins for Eclipse. These are provided with the IBM Redbook “Customizing and Extending IBM Content Navigator.” The “SG248055.zip” file contains many additional resources referenced in the Redbook. The plug-in files are located in “SG248055/usecases/Chapter 3 Setting up the development environment.”
The specific files you need are:
- com.ibm.ecm.icn.facet.EDSPlugin.202.jar
- com.ibm.ecm.icn.plugin.202.jar
To install the plug-ins for Eclipse, follow the steps below:
- Copy the two .jar plug-in files to the “dropins” directory within your Eclipse install: “C:/path/to/eclipse/dropins“
- Restart Eclipse
For each plug-in you develop, you will also need to reference the navigatorAPI.jar file located within the “lib” directory of the IBM Content Navigator installation directory. You can copy this .jar file to the machine you are developing on so it is available for each plug-in developed.
Once your Eclipse environment has been set up with the necessary plug-ins described above, you will be able to select “Content Navigator Plug-in” as a new project as shown in the image below. Simply follow the New Project wizard to create the new plug-in.
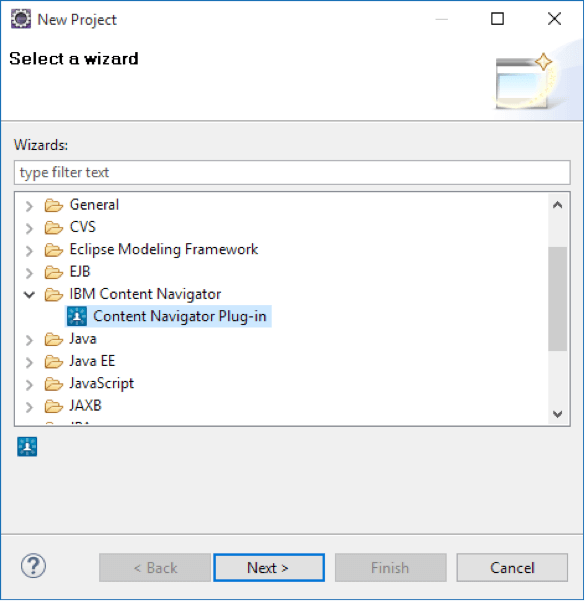
Overview of Plug-In Project Structure
All newly created plug-in projects start with the same base structure. See the sample plug-in project structure below.
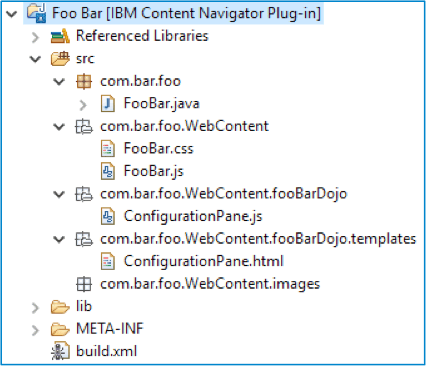
The root of the project contains a “build.xml” file, as well as a “src” directory.
The “src” directory contains all of the plug-in assets. At the base of the Java package directory is the plug-in .java file. All new .java files that are added to the plug-in to include new functionality will be added here.
The “WebContent” directory contains all of the client-side assets, including: .js, .css, .html, and all images. The root of the directory contains the initial .js and .css plug-in files. The plug-in .js file handles all global scope functions. The plug-in .css file contains all plug-in related styles you wish to include.
The plug-in dojo module directory also resides in the “WebContent” directory. This is where all dojo modules should reside, as they can be loaded through the AMD loader using the following syntax:
“dojoModuleName/ModuleName”
Using the above image of a sample plug-in structure, loading the “ConfigurationPane” dijit through the AMD loader would look like:
“fooBarDojo/ConfigurationPane”
The “build.xml” file is an Ant script used to build the plug-in. It contains information necessary to build the plug-in, including libraries necessary to build as well as information about the resulting .jar plug-in file.
Understanding the Plug-In .java File
The plug-in .java file that is initially included with all newly created plug-ins is responsible for referencing all new functional properties, as well as other important settings. Important properties to make note of include:
- getVersion() – Returns the String version number, which is displayed when installing the plug-in
- getDebugScript() – Returns the String file name of the debug version of the plug-in .js file
- getDebugCSSFileName – Returns the String file name of the debug version of the plug-in .css file
NOTE: Having a debug version of both your plug-in .js and .css files is helpful when you wish to have the ability to debug your code in a production environment, as it is a best practice to compress all client-side assets for best performance. To enter debug mode in IBM Content Navigator, simply append “&debug=true” to the URL.
Building the Plug-in Using Build.xml
Building the .jar plug-in file is a straightforward process. The included “build.xml” file is an Ant script and can be run to build the plug-in. To do this, follow the steps below:
- Right-click the “build.xml” file
- Select “Run As”
- Select “Ant Build
Eclipse’s console will log information related to the building process being performed, including errors that occurred as well as when the build has completed. The resulting .jar plug-in file will be at the root of the project.

Adding Functionality to the Plug-In
A base plug-in has no functional purpose. It is necessary to add new functionality to the plug-in. Luckily, IBM has made adding new functionality to a plug-in a simple process. To add new functionality to the project, follow the steps below:
- Right-click the Java Package
- Hover over the “IBM Content Navigator” menu option
- Select the new functionality you wish to add to the plug-in
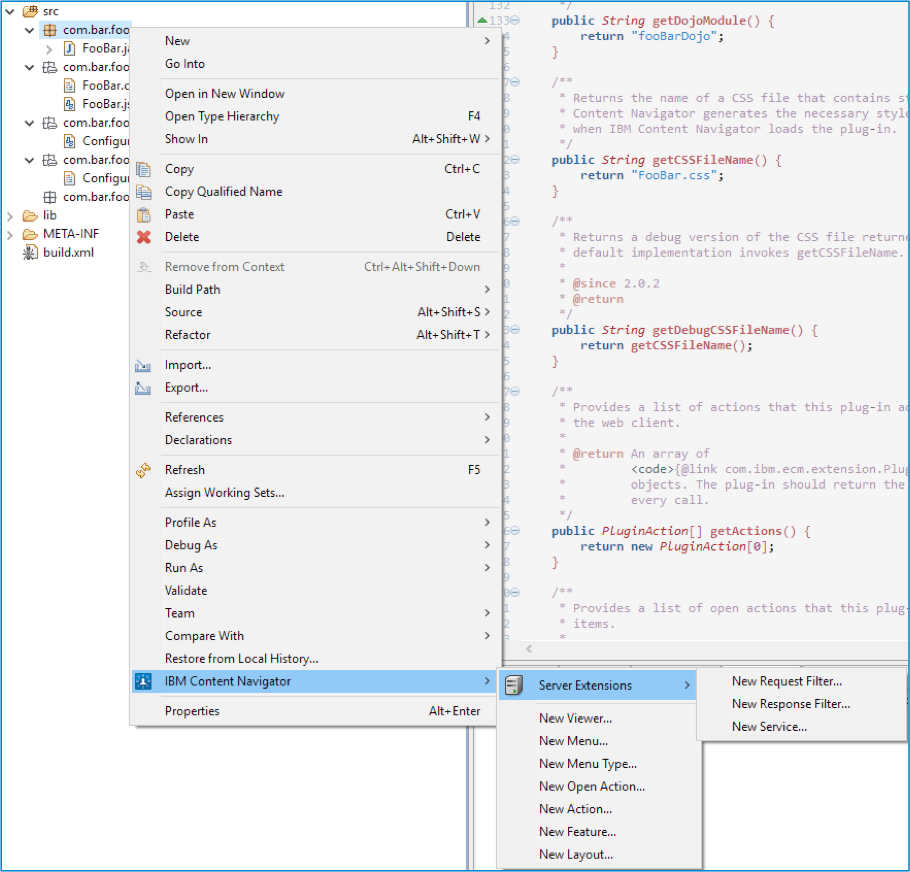
Doing this will add a reference to the newly created functionality to the plug-in .java file. It will also create other necessary files, or edit the plug-in .js file. For example, adding a new Feature will add a Feature dijit to the dojo module package, while adding a new Action will just include a Javascript function to the plug-in .js file which gets called when the Action is invoked.
Creating a Configurable Plug-In
Plug-in developers have the ability to include configurable options available when installing the plug-in in IBM Content Navigator. The configuration options will then be available to all plug-in services, through the “callbacks” parameter.
By default, all new plug-ins are created with a “ConfigurationPane.js” dijit at the root of the dojo module, which extends the “ecm.widget.admin.PluginConfigurationPane” class. The plug-in .java also reference this dijit from the public function “getConfigurationDijitClass()”
Configuration Template
To create configuration options available when installing the Content Navigator plug-in, you will need to edit the HTML template file for the ConfigurationPane dijit. One key aspect to keep in mind when developing the template file is the input fields need to have their content communicated to the .js of the dijit. For example:
<code>
<label for=”${id}_foobar_param”>Foo Bar</label>
<div id=”${id}_foobar_param” data-dojo-attach-point=”fooBarField” data-dojo-attach-event=”onKeyUp: _onParamChange” data-dojo-type=”ecm.widget.TextBox”>
</code>
The above code sample creates a text box “Foo Bar” which will call the “_onParamChange()” function each time a user modifies the text box.
Configuration Client-Side Script
The .js of the dijit needs to handle the initial population of the configuration options, as well as the saving of the configurations when the user clicks the “Save” button for the plug-in. Using the template above as an example, the code below does this:
<code>
load: function(callback) {
if (this.configurationString) {
var jsonConfig = JSON.parse(this.configurationString);
this.fooBarField.set(‘value’, jsonConfig.configuration[0].value);
}
},
_onParamChange: function() {
var configArray = [];
var configString = {
name: ‘fooBarField’,
value: this.fooBarField.get(‘value’)
};
configArray.push(configString);
var configJSON = {
configuration: configArray
};
this.configurationString = JSON.stringify(configJSON);
this.onSaveNeeded(true);
}
</code>
All plug-in configuration data can be accessed from the dijit’s “configurationString” property. Within the “load()” function, you need to parse the JSON object if it exists, then set the appropriate input fields to that stored value.
Because the dijit does not handle the actual saving of the configuration data, it is necessary to keep the “configurationString” dijit property up-to-date at all times. We do this through the event connection to the input element outlined in the template above. Within the “_onParamChanged()” function, we need to extract the value of the input, then create a JSON object based on those configurations and set the “configurationString” dijit property to that object.
Another important thing to note is that the save buttons on the plug-in configuration page are disabled by default, and have to be manually activated based on values getting changed. This is done through the “onSaveNeeded(true)” function call on the dijit, which communicates that the save buttons should be activated.
Accessing the Configuration Data
All configuration data can be accessed from any plug-in service. To get the values, simply use the below API call from within the “execute()” function:
<code>
String configuration = callbacks.loadConfiguration();
</code>
The “loadConfiguration()” function on the “callbacks” parameter of the “execute()” function returns the JSON object set by the “ConfigurationPane” dijit.
Loading Assets from Other Plug-Ins
It is possible to load assets from other plug-ins. The most common use-case is loading a commonly shared dijit to a new plug-in. This can be accomplished by following the below syntax for loading a dijit through the AMD loader:
“/navigator/plugin/FooBar/getResource/fooBarDojo/ConfigurationPane.js”
For those who are looking for specific IBM Content Navigator plug-in functions, check out this short video about Pyramid eXpeditor for Content.
Ready for the next step in developing more advanced IBM Content Navigator plug-ins? Check out my other blog about advanced plug-in service development. Click on the image below to read it.
