
It seems like every day there is a new IBM Watson tool for us to learn about. The ones that catch my attention are the ones that integrate with my world – a world that revolves around content and the services required to make the most of it. While at IBM Think, I had the opportunity to learn about Watson Visual Recognition and how it can be used to classify incoming content.
What is Watson Visual Recognition?
The name pretty much says it all. This technology is an IBM Cloud service that inspects images and suggests appropriate classification tags to ensure you’re able to find it later when needed. There are out-of-the-box recognition capabilities, and more importantly, the ability to train the tool and classify your own images. The Watson Visual Recognition services that are offered out of the box include:
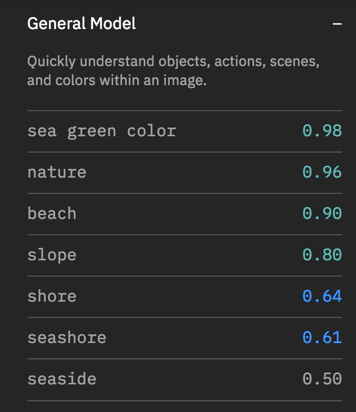
- General Model – What is this image?
This model works for generic images. Here’s an example. The model assigns “tags” based on its recognition of the image. The color-coded numbers are the confidence levels (1.0 being 100% confidence).

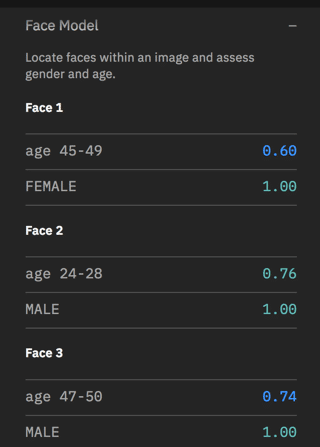

This model marks the location of faces. It even makes an attempt at age. (Don’t be offended if it overestimates your age, it’s only software after all!)

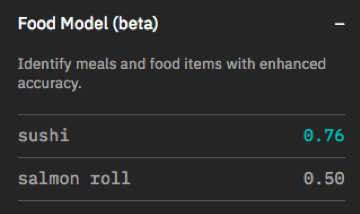
Watson Industry Use Cases of Watson Visual Recognition
These models are interesting and fun to play with, but they probably won’t provide much business value to your industry use cases.
This is where it gets fun.
You can use your own images to train the Watson Visual Recognition engine and create your own model. If you’ve used the IBM Content Classification Engine, the concept is similar. Using the Visual Recognition web tooling, or Datacap, you can create a new classifier, define classes (or categories), and train it with sample data.
For example, in the medical field, you may have four classes: X-Ray, EKG, MRI, and a Stress Test.
In the insurance field, your classes might be vehicle damage, house damage, license plate, driver’s license.
While at IBM Think, I attended a lab on Watson Visual Recognition. We created a ClaimDocs Classifier with the four classes seen in the image. Here’s what the output looked like:
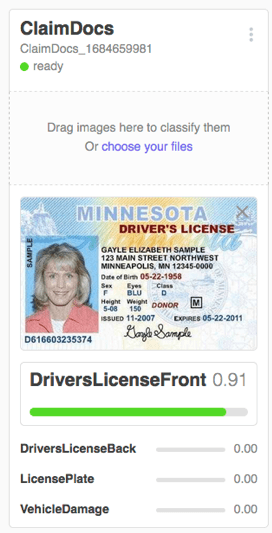
Again, the resulting number is the confidence level. When calling the classifier using the APIs, or Datacap, you can configure what confidence to accept.
This is where the power of Watson Visual Recognition comes from. You can define custom classifiers that are applicable to your industry. The sky’s the limit, you simply must have the images with which to train.
What Does This Have to do With Datacap?
Datacap has always been good at recognizing and classifying textual documents. Datacap has all kinds of tools to do this: keywords, barcodes, fingerprints, and even the content of the document. But all these methods assume a text document. Datacap has never been able to do anything with pictures … until now.
With Datacap 9.1.3, there is an out-of-the-box integration to the Watson Visual Recognition Service. There are actions to train the model and use it for classification.
If you use Datacap as your ingestion method for customer documents, why limit it to traditional text?
The Down and Dirty of It
For those of you who are Datacap geeks (like me), here are the details. If you don’t care to dig into the depths of DStudio, you can doze off for a few paragraphs.
There is a total of four actions to integrate with Watson Visual Recognition.
- Set Watson Credentials
- Set the minimum confidence level you require
- Train the model
- Classify unknown documents
That’s it.
Training a Visual Recognition Model
Basically, training involves creating the classes within your model, then feeding as many example documents as you can – the more, the better. This can be done in one of several ways.
- Use Watson Studio to manually create classes and manually add your example docs one at a time.
- Upload a zip file to each class that contains the documents for that class.
- Use the Watson APIs to programmatically train your model.
But since this is a Datacap blog, of course, we will use Datacap to do this.
The Watson Visual Recognition Service requires the training documents to be either JPG or PDF format. It also expects these files to be organized into zip files. The VisualRecogTrain action expects that each set of test pages are in one document per class. All this can be accomplished in your application rulesets.
- In your Datacap application, you’d convert the file (if necessary) and set the page type of the example docs.
- Then compile like page types into one document.
- Finally, call VisualRecogTrain with a location for the zip file, and the name you want to call your classifier. There’s also a parameter to set whether you want to overlay an existing model or add to it.
- Once this ruleset completes, you should be able to log on and see (and test) your model in Knowledge Studio. Depending on the number of training documents, the model will take a few minutes to complete.
Using a Visual Recognition Model
Once you create a model from Datacap and it’s in Ready Status, you can use your model to classify unknown images. You can do this through the Watson web interface, or (of course) from Datacap. Think of Visual Recognition in the same way as any other classification. It runs during PageID, the page is sent to the service, and the service sends back the classification and a confidence level. You can set a minimum confidence level to accept. The classification ruleset would look something like this:

What Can I do With All This?
By now you might be starting to think of the possibilities.
At Pyramid Solutions, one of our core focuses is the insurance industry. The use case for this is obvious. Claim submission packages will typically include photos. Wouldn’t it be great if Datacap could classify the incoming claim photos? Let’s say ‘automobile’ for example.
But why stop there? Maybe it could be as specific as a flat tire or a broken window. And for that matter, if trained properly, maybe it could suggest whether this was simply a fender bender or a total loss. And after making that decision, route the claim to the appropriate agent.
Or, what about medical documents. Watson Visual Recognition could be trained to recognize an x-ray of lungs, versus a broken bone. Or perhaps used to recognize the difference between a skin mark that is normal, versus cancerous.
There could be use cases for building inspections, using drone images to tell the difference between a roof in good condition and one needing repair.
There’s even a use case for using aerial imagery to identify land parcels that are using too much water in drought conditions in California. I did not make that one up, you can even read about that use case here.
Think about your industry and the work that you do.
What photos do you process on a regular basis?
Are you already using Datacap to ingest other documents into your line of business systems?
Can you think of any ways that Watson Visual Recognition can make your processing of photos less manual?
I’d love to hear about any use cases you can think of – connect with me on LinkedIn and let me know!
If you want to learn more about Watson Visual Recognition, here’s a nice collection of learning resources: “25+ Resources for Watson Visual Recognition.”

Stephanie Kiefer Jefferson
Solution Consultant