
By Kevin Knill, Director of Products and Services
One of the most common questions clients ask us is how to best define the document taxonomy within their content management system. You see, there is a tendency to overload documents with an exhaustive list of properties that one might use to find it. At first blush, this appears to make sense — if I want to find a document, why not provide all of the possible search criteria information? However, in an effort to be thorough and inclusive, users end up limiting themselves with this approach.
Let’s consider some common key issues we see when it comes to document taxonomy:
- Properties are too vague.
In most enterprise applications, documents serve many purposes. A document used to underwrite an insurance policy can also be used in a claim. But many of the properties used to describe the document for underwriting do not pertain to the claim and vice versa.To clearly characterize the document as it is used, it needs different properties for each unique business processes. If all these properties are added to the document, the outcome is a system that is hard to configure and maintain. - Information may be inconsistent.
Organizations use and reuse documents over many years. If a user indexes a document for an onboarding process, the information is quite different when it is later applied to a claim. Showing document information that is relevant to a particular process then becomes a significant challenge. - Indexing takes too much time.
Who is doing all that indexing? Like I mentioned above, documents come into play during many different processes over the years and updating these properties is a chore. Processors and underwriters waste valuable time doing this manual work, which is also something that wasn’t in their job description. - Business requirements change too much.
Continuing along this theme of manual work, the next challenge is changing business requirements. Just like how if a processor applies a document to a different process, any changes in business requirements require the processor to manually update properties on all existing documents. - Changes to a document need to be updated and uploaded.
To overcome some of the issues above, we see organizations print and scan a document to use it in a different process. However, if there is a change to the document or a new version provided, the processor must find and replace every copy of the document. The task is both costly and error-prone.
As an example of what overloading a document actually does to you, let’s consider a case of an attending physician’s statement (APS) (basically a comprehensive medical history document) indexed by:
- Document type
- Patient name
- Physician’s name
- Date of issue
- Application number
- Policy face value
- Type of policy
- Claim number
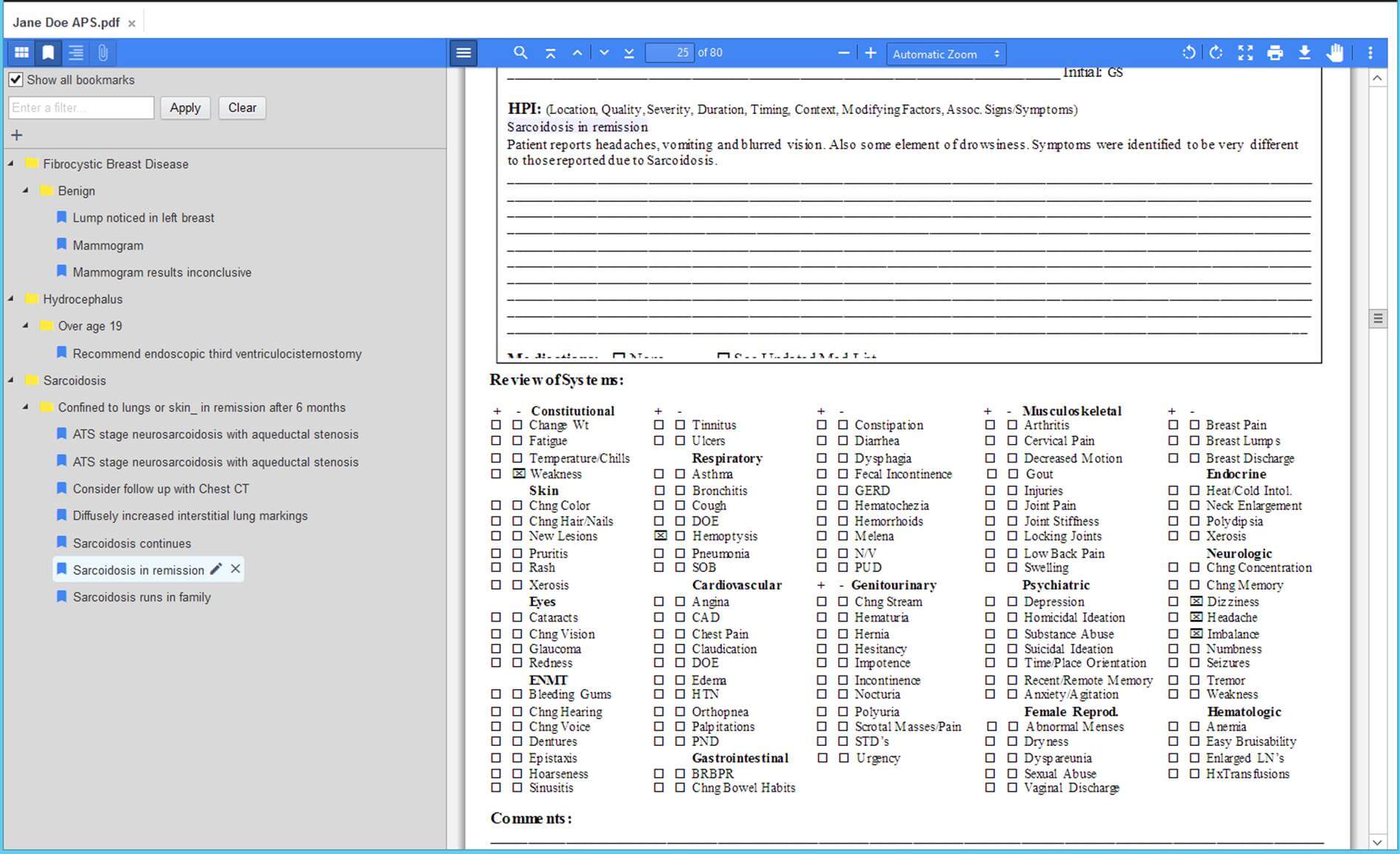 Screenshot of our APS viewer.
Screenshot of our APS viewer.
The first four properties refer specifically to the document. However, the last four properties are part of an application or claim process. If the face value property changes, each document collected as part of that application must change as well, wasting time, work and productivity.
In addition, the claim number is typically blank during the underwriting process but filled in at a later time when a claim is actually filed. If an insurer uses the APS for multiple claims, then this property will need to support multiple claim numbers. This significantly increases the complexity of managing the document.
Another example would be when an enterprise later adds a policy administration system. Then they must update every document with a policy number property class.
As you can see (and probably experience first-hand), document management challenges quickly become complex when overloading documents with process properties.
A Better Way to Document Indexing
Pyramid Solutions advocates a lean indexing approach whereby document properties simply describe the document and not the process properties.
In our above APS example, we recommend indexing a document by type, patient name, physician name and the date of issue. Whether an insurer uses it to underwrite multiple insurance policies or it’s solely part of a claim, these properties will remain meaningful and accurate over the life of the document.
All other properties (application number, policy face value, type of policy and claim number) would classify where and how the APS document was used and they should be added to the definition of the folders. There may be separate folder types for onboarding, underwriting, policy administration, claims and rescission. Each of these folders has its own set of process-specific properties.
Since each folder references the same, single document, if any user changes a document property or uploads a new document version, the changes immediately proliferate to all folders.
To effectively use this lean taxonomy strategy, it’s important to have the right tools. In your content management system, here are some things to look for:
- Search Functionality
A search function that searches for and through folders, documents or documents within folders, and provides filtered results by both folder and document properties. This ensures that you quickly find the appropriate documents for each process. - Document Tagging
A way to tag documents by a process. Processors can then characterize the document by the part it plays in the process without overloading the taxonomy. For example, a document could be designated “part of the decision” for one process or “under review” for another. - Document Bookmarking
A way to bookmark documents by a process to highlight salient features. Processors can then identify key, process-specific information in documents without overloading the taxonomy. You will also need a viewer that is able to distinguish between bookmarks applicable to each process. - Security
Document security policies that support process-centric access rights.
Developing an enterprise document taxonomy strategy requires careful thought and planning. By utilizing a lean approach that’s wrapped in a process-centric folder structure and accompanied by appropriate viewing tools, you will be able to implement an enterprise architecture that is robust, flexible and extensible.
If you want to learn more, check out Pyramid eXpeditor for Content or talk to one of our experienced solution architects about design and planning efforts.